-
통계-1 연속형 데이터통계 2023. 5. 29. 16:18
1. 연속형 데이터
연속형 데이터는 말 그대로 연속적인 값으로 이루어진 데이터이다. 온도, 길이, 시간 등이 연속형 데이터에 포함된다.
2. 히스토그램
import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv("./BlackFriday.csv") user_total_spent = data.groupby('User_ID')["Purchase"].sum()모듈을 불러오고 blackfriday.csv 파일을 읽어온 후 userid당 purchase를 합산한다.
plt.hist(user_total_spent, bins=50) plt.title('histogram of total purchase amount by user') plt.xlabel('total purcahse amount') plt.ylabel('frequency') plt.show()
총 구매 가격 당 사용자의 빈도를 히스토그램으로 그릴 수 있다. 0~20000달러 사이에 사용자가 가장 많이 분포하며 구매 가격이 상승할수록 사용자의 빈도가 떨어지는 연속적인 값을 가진다.
3. 밀도 그래프
plt.figure() user_total_spent.plot.kde() plt.title('destiny plot amount total purchase amount by user') plt.xlabel('total purchase amount') plt.show()
밀도 그래프는 히스토그램과 달리 부드로운 곡선으로 표현할 수 있다. 어떤 구간에서 분포도가 높은지 확인할 수 있다.
kde 함수다 그래프를 곡선으로 만들어준다.
4. 확률밀도함수(probability density function, pdf)
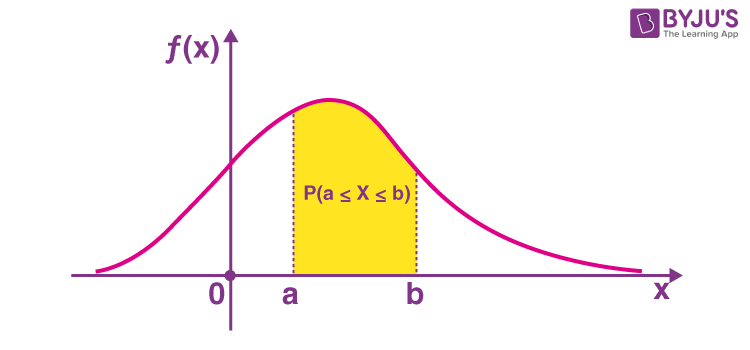
확률밀도 함수란 확률의 값이 구간 내에서 어떻게 분포하는지를 의미한다. 밀도 그래프에서 특정 구간이 차지하는 만큼 전체 변수 중에서 특정 값이 나올 확률을 의미하는 것이다.
5. 정규 분포

정규분포는 초창기 통계학자들이 서로 다른 그래프에서 같은 모양이 나타나는 것을 보고 정규분포라고 명명했으며 위와 같은 종 모양을 가진다.
6. 중심 경향성
중심 경향성은 중심이 어디있는지를 나타내는 지표이며 평균값, 중앙값, 최빈값이 해당된다.
평균값 : 평균은 데이터 값의 총합을 데이터의 개수로 나눈 값이다.
중앙값: 중앙값은 데이터를 크기 순서대로 정렬했을 때 가운데 위치한 값이다.
최빈값: 최빈값은 데이터에서 가장 많이 분포되어 있는 값이다.
data = np.random.normal(loc=0, scale=1,size=1000) sns.histplot(data) plt.show() mean = np.mean(data) median = np.median(data) print('mean: ',mean) print('median: ',median) mean: 0.0007027880117535936 median: 0.030026396291816686
random.normal 함수로 임의의 값을 정규분포 형태로 생성한다. 0을 기준으로 표준편차는 1, 1000개의 값을 임의로 생성한다.
mean 함수를 사용하여 평균값, median 함수를 사용하여 중앙값을 확인할 수 있다.
7. 산포도
산포도는 데이터가 얼마나 분산되어있는지 분산 정도를 나타내는 그래프이다.
np.random.seed(0) x= np.random.normal(loc=0,scale=1,size=100) y= x+np.random.normal(loc=0,scale=0.5,size=100) fig, ax = plt.subplots() ax.scatter(x, y) ax.set_xlabel('X') ax.set_ylabel('Y') ax.set_title('Scatter Plot') plt.show()
np.random.seed는 넣어주는 숫자의 값에 따라 난수가 출력된다. x 값 100개, y는 x값을 더해주어 선형적인 모양을 띄도록 만든다. x가 증가할수록 y도 증가한다.
8. 이상치
이상치는 대부분의 데이터가 분포해 있는 구간이 아닌 극단적으로 벗어나 있는 값을 나타낸다.
data = np.concatenate([np.random.normal(0, 1,900), np.random.normal(8,2,100), np.random.normal(-4,2,100)])fig, ax = plt.subplots() ax.boxplot(data) ax.set_xlabel('Data') ax.set_ylabel('Values') ax.set_title('Box Plot') plt.show()
np.concatenate 함수를 사용하여 생성한 난수의 값들을 합친다.
box plot함수를 사용하여 box plot 그래프를 그린다. 상자 안 선은 중앙값, 상자의 윗면과 아랫면은 각각 3 사분위(q3), 1 사분위(q1)로 데이터의 75퍼센트와 25퍼센트를 의미한다.
1.5*iqr을 넘어가는 부분인 하얀색 원들은 이상치를 의미한다.
하얀색 원, 아웃라이어가 시작되는 선은 각각 최대값과 최솟값을 나타내며 q3-q1 즉 데이터의 50% 범위를 사분위 범위(iqr)이라고 부른다.
fig, ax = plt.subplots() ax.hist(data, bins=50) ax.set_xlabel('Data') ax.set_ylabel('Frequency') ax.set_title('Histogram') plt.show()
히스토그램으로 그려보면 박스 플롯처럼 이상치를 확인할 수 있다.
9. 상관관계
상관관계는 두 변수 사이에 어떤 관련성이 있는지를 나타낸다. 한 변수가 변화할 때 다른 변수는 어떻게 변화하는지를 알 수 있으며 1에서 -1 사이의 값으로 나타내고 이것을 상관계수(correlation coefficient)라고 한다.
np.random.seed(123) x=np.random.normal(loc=0,scale=1,size=100) y=10*x+np.random.normal(loc=0,scale=1,size=100) fig, ax = plt.subplots() ax.scatter(x, y) ax.set_xlabel('X') ax.set_ylabel('Y') ax.set_title('Scatter Plot') plt.show()
랜덤한 x를 100개 생성하고 y의 값은 x와 선형적인 관계를 띄도록 x *10을 해서 난수를 더한다. 이를 scatter로 그려보면 선형적인 모양인 것을 확인할 수 있다.
corr = np.corrcoef(x,y)[0,1] print('상관계수', corr) 상관계수 0.9963133498326883np.corrcoef 함수를 사용하여 x와 y의 상관관계를 확인하면 0.99가 나타난다. 즉 x와 y는 양의 상관계수를 가면서 두 변수 간의 선형관계가 매우 강하다는 것을 알 수 있다.
'통계' 카테고리의 다른 글
통계-5 데이터 분석 방법 (0) 2023.05.29 통계-4 순서형 데이터, 이진 데이터, 시계열 데이터, 공간 데이터 (0) 2023.05.29 통계-3 범주형 데이터 (0) 2023.05.29 통계-2 이산형 데이터 (0) 2023.05.29