-
sklearn-05 모델 평가 지표머신러닝/sklearn 2023. 5. 4. 20:03
1. 모델 평가 지표
모델의 성능을 평가하는 여러 가지 지표이다.
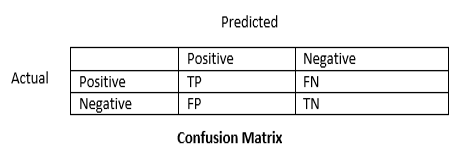
confusion matrix: 혼합 행렬은 예측값과 실제값을 표로 나타낸 것이다.
presicion : 정밀도는 true라고 예상한 값 중에서 실제 true의 비율이다. (TP/TP+FP)
recall : 재현율은 실제 true인 값중에서 true라고 예측한 값의 비율이다. (TP/TP+FN)
accuracy : 정확도는 실제 true를 true로 실제 false를 false로 예측한 값의 비율이다. (TP+TN/TP+FN+FP+TN)
f1 score : precision과 recall의 조화 평균값이다. (2/1/recall+1/precision)
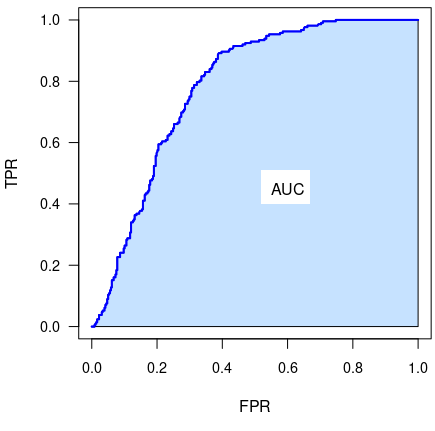
roc(receiver operating characteristic) curve : 어떤 모델이 좋은 성능을 보이는지 판단할 때 사용한다.
tpr(true positive rate) : 실제 true인 값을 true라고 예측한 비율 즉 recall값이다.
fpr(false positive rate) : 실제 false인 값을 true로 틀리게 예측한 비율이다.
auc(area of the roc curve) : roc curve의 밑면을 의미하며 auc 면적이 넓을수록 좋은 모델이다.
2. 회귀모델 평가지표

mae(mean absolute error) : 오차에 절댓값을 씌워 평균을 구하는 함수이다.
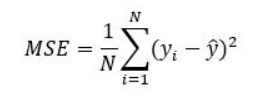
mse(mean of squared error) : 오차를 제곱하여 양수로 만든 후 평균을 구하는 함수이다.
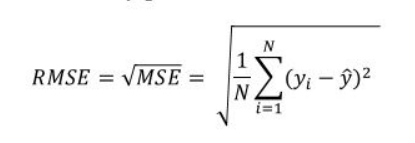
rmse(root mean squared error) : mse에 루트를 씌운 값이다.
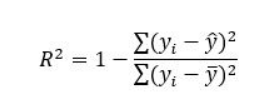
r2(결정계수) : 원래 값과 비교하여 값이 얼마나 잘 맞는지에 대한 계수를 나타낸다. 0에서 1 사이의 값은 백분율로 해석되며 값이 높을수록 모델이 더 좋다.
3. 오버피팅과 언더피팅
모델을 학습하여 정확도만 높다고 좋은 모델이라고 말할 수 없다. 그것은 하나의 데이터에 대하여 정확도가 높은 것일 뿐 새로운 데이터에 대해서는 정확도가 낮을 수도 있다.
이러한 현상을 오버피팅이라고 하며 반대로 정확도가 낮은 상황을 언더피팅이라고 한다.
데이터 학습의 목적은 새로운 데이터에도 높은 적응률을 보이며 정확도를 최대한 높이는 것이며 그 과정에서 cpu, gpu의 성능과 효율측면도 강조될 것이다.
'머신러닝 > sklearn' 카테고리의 다른 글
sklearn-04 preprocessing 4 categorical variable to numeric variable (0) 2023.05.07 sklearn-03 preprocessing 3 dimensionality reduction (0) 2023.05.07 sklearn-02 preprocessing 2 sampling (0) 2023.05.07 sklearn-01 preprocessing 1 scaling (0) 2023.05.04