-
sklearn-14 clustering 1 hierarchical clustering, silhouette머신러닝/sklearn 2023. 5. 10. 18:11
1. hierarchical clustering
계층적 군집화는 여러 개의 군집 중에서 가장 가장 가까운 군집 두 개를 하나로 합치면서 군집 개수를 줄여가는 방법이다.

1. 거리가 가까운 데이터를 찾고 묶는다.
2. 가까운 클러스터끼리 병합한다.
3. 1개의 클러스터가 될때가지 반복한다.
4. 클러스터를 원하는 모양으로 나눈다.
2. python
from sklearn.cluster import AgglomerativeClustering single_clustering = AgglomerativeClustering(n_clusters=3, linkage='single') single_clustering.fit(data) single_cluster = single_clustering.labels_ single_cluster array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])필요한 모듈을 불러오고 군집 수와 분류 방법을 선택한다. 데이터를 학습하고 배열을 출력한다.
plt.scatter(data[:,0],data[:,1],c=single_cluster)
single linkage는 두 클러스터 사이의 가장 가까운 점을 기준으로 클러스터를 형성하기 때문에 멀리 떨어진 데이터 한두 개만 군집을 따로 형성한 것을 확인할 수 있다.
complete_clustering = AgglomerativeClustering(n_clusters=3, linkage='complete') complete_clustering.fit(data) complete_cluster = complete_clustering.labels_ complete_cluster array([1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])군집 수와 분류 방법을 선택한다. 데이터를 학습하고 배열을 출력한다.
plt.scatter(data[:,0],data[:,1],c=complete_cluster)
complete linkage는 두 클러스터 사이의 가장 먼점을 기준으로 클러스터를 형성하여 적절히 분포된 것을 볼 수 있다.
이외에도 평균 거리에 따라 군집을 형성하는 average linkage가 있다.
from scipy import show_config from scipy.cluster.hierarchy import dendrogram children = complete_clustering.children_ distance = np.arange(children.shape[0]) no_of_observations = np.arange(2, children.shape[0]+2) linkage_matrix = np.column_stack([children,distance, no_of_observations]).astype(float) dendrogram(linkage_matrix, p = len(data), labels = complete_cluster, show_contracted=True, no_labels =True)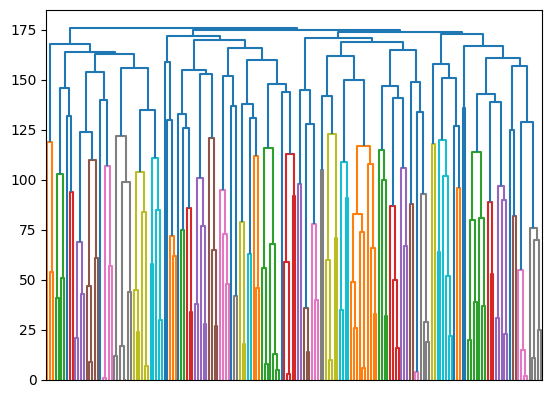
과학적인 연산을 위한 scipy 모듈을 불러온다. 덴드로그램을 불러온다. 자식 노드에 대한 정보를 가져오고 거리를 구한다.
노드의 수를 계산하는데 노드의 수는 루트노드 + 인덱스이기 때문에 +2를 한다.
마지막으로 덴드로그램을 그린다.
3. silhouette
실루엣은 가장 좋은 클러스터를 형성하는 클러스터의 수를 찾는 방법이다.
실루엣 계수는 -1 에서 1 사이의 값을 가지며, 1로 가까워질수록 근처의 군집과 더 멀리 떨어져 있다는 것이고, 0에 가까울수록 근처의 군집과 가까워진다는 것이다.
from sklearn.metrics import silhouette_score best_n = -1 best_score = -1 for n_cluster in range(2,11): kmeans =KMeans(n_clusters=n_cluster) kmeans.fit(data) cluster = kmeans.predict(data) # 실루엣 함수 score = silhouette_score(data, cluster) print('Cluster count:{} Silhouette Score:{:.2f}'.format(n_cluster,score)) if score>best_score: best_n = n_cluster best_score = score print('\n------------\n') print('best n_cluster: {} silhouette Score {:.2f}'.format(best_n, best_score)) Cluster count:2 Silhouette Score:0.49 Cluster count:3 Silhouette Score:0.57 Cluster count:4 Silhouette Score:0.49 Cluster count:5 Silhouette Score:0.46 Cluster count:6 Silhouette Score:0.43 Cluster count:7 Silhouette Score:0.39 Cluster count:8 Silhouette Score:0.40 Cluster count:9 Silhouette Score:0.39 Cluster count:10 Silhouette Score:0.38 ------------ best n_cluster: 3 silhouette Score 0.572에서 11까지의 클러스터의 수를 변경해가며 실루엣 점수를 확인하고 가장 점수가 높은 클러스터 수를 출력한다.
'머신러닝 > sklearn' 카테고리의 다른 글
sklearn-13 clustering 1 kmeans (0) 2023.05.10 sklearn-12 regression 3 svr (0) 2023.05.10 sklearn-11 regression 2 decison tree regressor (0) 2023.05.10 sklearn-10 regression 1 linear regression (0) 2023.05.10