-
keras-2 imdb딥러닝/keras 2023. 5. 23. 17:20
1. python
from keras.datasets import imdb (train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000)케라스에 있는 imdb 데이터셋을 불러온다.
train_data.shape (25000,) train_labels[0:5] array([1, 0, 0, 1, 0]) max([max(sequence) for sequence in train_data]) 9999데이터가 두 가지로 나뉘어 있고 25000개의 훈련 데이터를 가지고 있다.
import numpy as np def vectorize_sequences(sequences, dimension=10000): result = np.zeros((len(sequences),dimension)) print(result.shape) for i, sequence in enumerate(sequences): result[i, sequence] = 1 return result세로가 25000, 가로가 10000개인 데이터를 출력하는 함수를 zeros를 사용하여 만든다.
enumrate를 사용하여 특정 위치가 1이 되게 만든다.
x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) (25000, 10000) (25000, 10000)훈련 데이터와 테스트 데이터를 확인한다.
x_train[0] array([0., 1., 1., ..., 0., 0., 0.])훈련 데이터의 첫번째 열을 확인한다.
y_train = np.asarray(train_labels).astype('float32') y_test = np.asarray(test_labels).astype('float32')라벨 데이터를 실수형으로 변경한다.
y_train[0] 1.0라벨 데이터가 실수형으로 출력된다.
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])레이어를 쌓기 위해 sequentail을 사용하고 16개의 유닛을 가진 렐루 은닉층 두 개와 시그모이드 함수로 이진 분류를 한다.
옵티마이저와 손실함수, 메트릭을 정한다.
x_val = x_train[:10000] partial_x_train = x_train[10000:] y_val = y_train[:10000] partial_y_train = y_train[10000:]10000개의 샘플을 만든다.
history = model.fit(partial_x_train, partial_y_train, epochs=4, batch_size=512, validation_data=(x_val, y_val)) Epoch 1/4 30/30 [==============================] - 2s 60ms/step - loss: 0.5198 - accuracy: 0.7795 - val_loss: 0.3876 - val_accuracy: 0.8665 Epoch 2/4 30/30 [==============================] - 1s 37ms/step - loss: 0.3171 - accuracy: 0.8925 - val_loss: 0.3156 - val_accuracy: 0.8787 Epoch 3/4 30/30 [==============================] - 1s 39ms/step - loss: 0.2415 - accuracy: 0.9171 - val_loss: 0.3023 - val_accuracy: 0.8760 Epoch 4/4 30/30 [==============================] - 1s 37ms/step - loss: 0.1970 - accuracy: 0.9339 - val_loss: 0.2752 - val_accuracy: 0.8891데이터를 학습한다. 4번 반복학습한다. batch size는 연산한번의 데이터 크기이다.
history_dict = history.history history_dict.keys() dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])history객체는 훈련한 정보를 가지고 있으며 4개의 항목을 가지고 있다.
import matplotlib.pyplot as plt acc = history.history['accuracy'] loss = history.history['loss'] val_acc = history.history['val_accuracy'] val_loss = history.history['val_loss'] epochs = range(1,len(acc)+1) plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'r-', label='Validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend()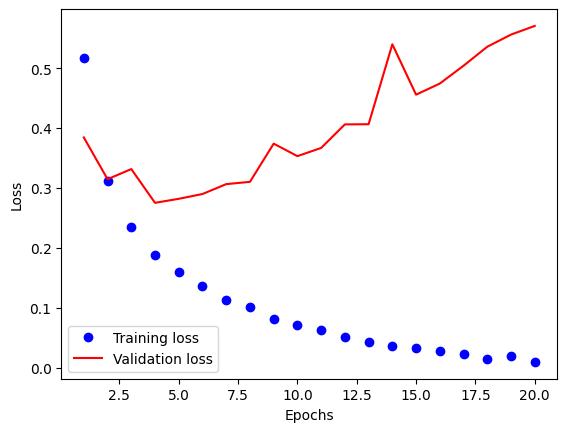
학습을 반복할 때마다 손실 함수를 그래프로 확인한다.
plt.plot(epochs, acc, 'bo', label='Training accuracy') plt.plot(epochs, val_acc, 'r-', label='Validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend()
학습을 반복할 때마다 정확도를 그래프로 확인한다.
model.predict(x_test) 782/782 [==============================] - 2s 2ms/step array([[0.24556442], [0.99899644], [0.93403685], ..., [0.0779324 ], [0.13249207], [0.39662933]], dtype=float32)훈련된 모델로 예측한다.
test_loss, test_acc = model.evaluate(x_test, y_test) print('loss={0}, accuracy={1}'.format(test_loss, test_acc)) 782/782 [==============================] - 3s 3ms/step - loss: 0.2911 - accuracy: 0.8825 loss=0.2911200225353241, accuracy=0.8825200200080872높은 정확도를 가지는 것을 확인할 수 있다.
'딥러닝 > keras' 카테고리의 다른 글
keras-6 cnn (0) 2023.05.29 keras-5 boston (0) 2023.05.29 keras-3 reuter (0) 2023.05.29 keras-1 mnist (0) 2023.05.23