-
음성 처리-1 이미지음성 처리 2023. 7. 4. 16:51
1. librosa
음성 데이터를 이미지로 변환하여 특징을 추출하고 처리하기 위한 python 라이브러리이다.
import matplotlib.pyplot as plt import numpy as np import soundfile as sf import librosa import librosa.display file = './data/blues.00001.wav' data, sr = librosa.load(file) duration = 10 samples = int(duration *sr) start =0 y = data[start:start+samples] spec = librosa.stft(y) spec_db = librosa.amplitude_to_db(np.abs(spec), ref=np.max) librosa.display.specshow(spec_db, sr=sr , y_axis='log',x_axis='time') plt.savefig('spec.png') plt.close()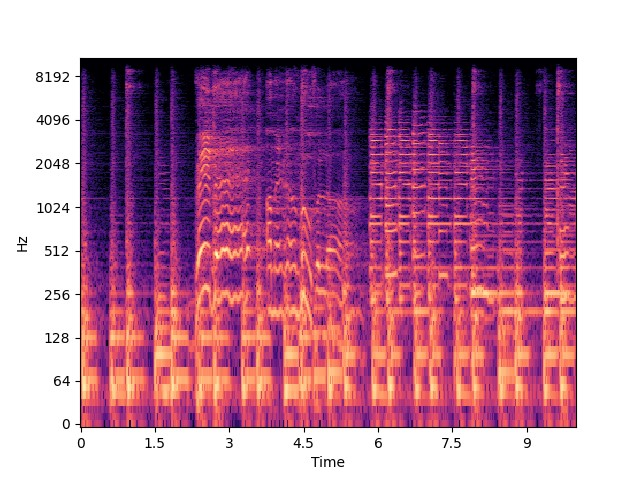
librosa 라이브러리를 설치하고 음성파일을 load 함수로 불러온다. 오디오 데이터와 샘플링속도(초당 샘플 수) 두 가지를 반환한다.
샘플링속도에 10을 곱해서 10초 동안 출력되도록 만들고 0초부터 10초까지 잘라서 y에 저장한다.
y를 stft함수에 넣는다. stft함수는 short time furier transform의 약자로 시간 도메인의 신호를 주파수 도메인의 신호로 변환하는 과정을 여러 번 반복하여 신호를 작게 분할한 후 각 단위에서 주파수 성분을 분석하는 것이다. 이 과정을 통해서 특정 시점에 대한 주파수 성분을 얻을 수 있다. sift 함수는 stft를 계산하여 복소수 행렬로 반환한다.
spec값을 amplitude_to_db 함수에 넣는다. amplitude_to_db는 데시벨 단위로 변환하는 역할을 하며 ref 인자는 기준값으로 max를 지정하면 최댓값을 기준으로 데시벨로 변환한다.
최종적으로 얻어진 spec_db를 가지고 데시벨 값을 specshow 함수로 시각화하며 샘플링 주파수를 지정해 준다.
2. mfcc(Mel-Frequency Cepstral Coefficient)
mfcc는 특징 추출방법 중 하나로 주파수 영역과 시간 영역을 효과적으로 나타낼 수 있다. 주파수 변환과정에서 인간의 청각 특성을 모델링한 멜 스케일을 필터로 사용한다.
y1, sr1 = librosa.load(file,sr=44100) print(sr) 22050 hop_length = 512 n_fft = 2048 stft = librosa.stft(y, n_fft=n_fft,hop_length=hop_length) n_mels =40 mel_spec = librosa.feature.melspectrogram(S=librosa.power_to_db(np.abs(stft)**2),sr=sr,n_mels=n_mels) n_mfcc =13 mfccs = librosa.feature.mfcc(S=librosa.power_to_db(mel_spec), n_mfcc=n_mfcc) plt.figure(figsize=(10,4)) librosa.display.specshow(mfccs,x_axis='time') plt.tight_layout() plt.savefig('mfcc.png',dpi=300,bbox_inches='tight') plt.close()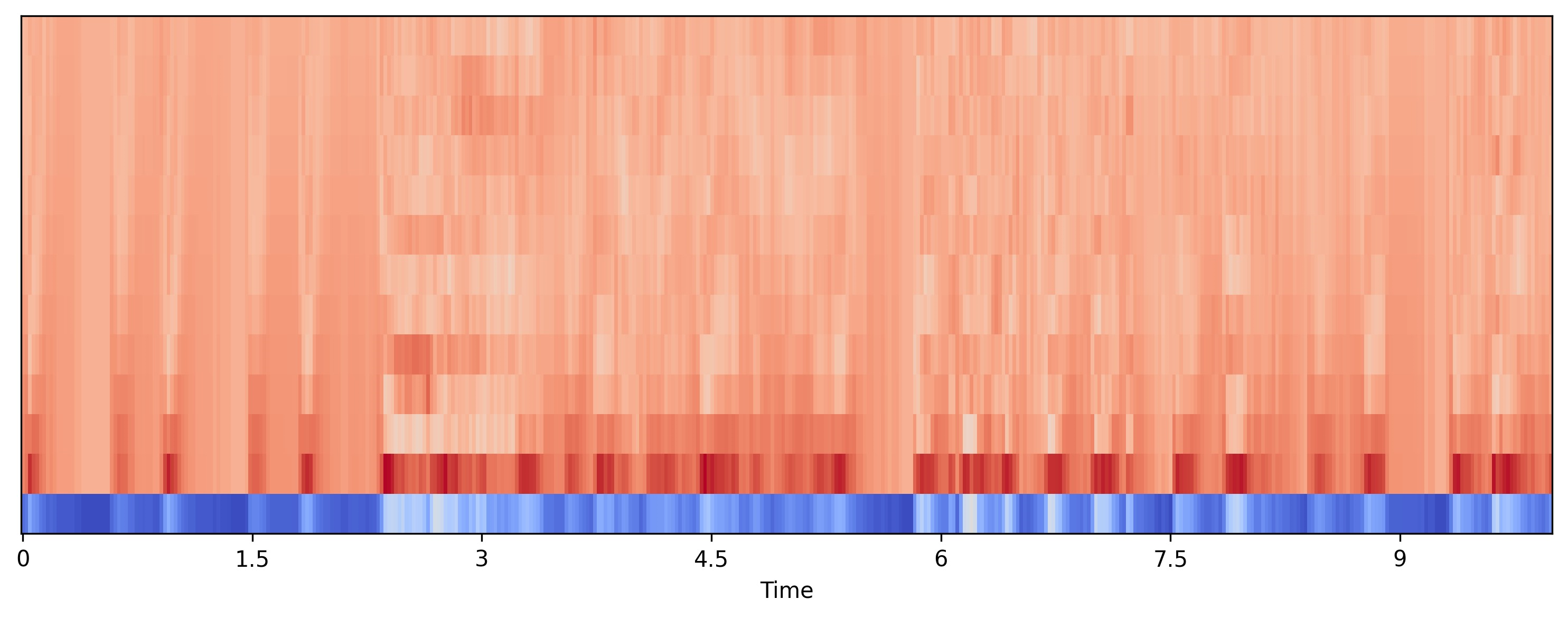
load를 할 때 sr을 44100으로 설정하여 44.1khz 속도로 로드한다. stft 계산을 할 때 n_fft는 fast foutier transform의 윈도우 크기로 주파수를 얼마나 세밀하게 분석할지 결정하며 값이 클수록 세밀해지지만 계산 비용이 증가한다. hop_length 인자는 프레임 간의 간격을 조절하며 값이 작을수록 많은 프레임이 생성되어 시간을 세밀하게 나눈다.
추출한 stft 값을 멜스펙토그램으로 변환한다. melspectogram() 함수를 사용하며 stft의 변수가 복소수 형태이기 때문에 절댓값을 제곱하여 파워 스펙토그램으로 변환한다. 이후 librosa.power_to_db()로 db로 변환하여 S 매개 변수에 넣는다. 샘플링 주파수와 mel 필터의 개수를 지정한다.
멜 스펙토그램을 ibrosa.power_to_db()로 db로 변환하고 추출할 mfcc의 개수를 지정하여 librosa.feature.mfcc() 함수에 넣으면 mfcc 스펙트럼을 계산할 수 있다.
mfcc 스펙트럼을 시각화하고 저장한다.
3. 잡음 생성
noise_amp = 0.5 *np.random.uniform()*np.max(data) noise = noise_amp*np.random.normal(size=data.shape) data_noise = data.astype('float32') + noise.astype('float32') save_path='./data/sample_noise.wav' sf.write(save_path,data_noise,sr) plt.figure(figsize=(20,5)) plt.subplot(1,2,1) plt.plot(data) plt.subplot(1,2,2) plt.plot(data_noise) plt.show() plt.close()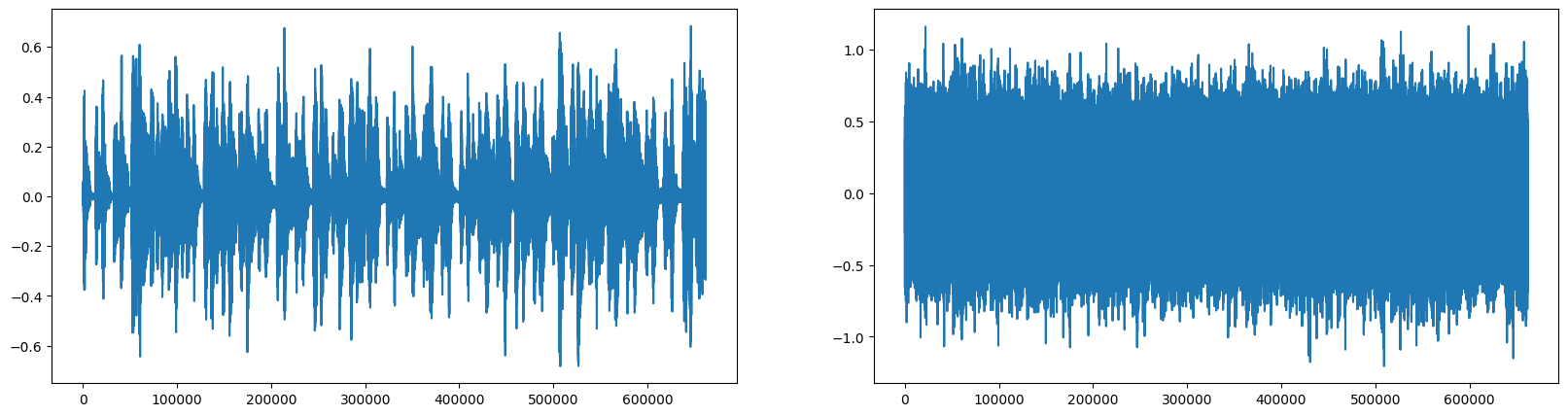
소리 데이터에 정규화 노이즈 무작위 값에 최댓값을 0.5배로 곱해서 noise_amp에 저장한다. noise_amp값에 소리 데이터와 같은 크기 랜덤 데이터를 생성하여 곱하고 noise에 저장한다.
기존의 소리 데이터와 정규화 노이즈가 곱해진 noise를 서로 float32으로 변환하여 더한다. 소리 데이터를 저장하고 그림으로 그려서 확인하면 정규화 노이즈가 추가된 것을 확인할 수 있다.
4. 스트레칭
data_stretch = librosa.effects.time_stretch(data,rate=0.8) plt.figure(figsize=(20,5)) plt.subplot(1,2,1) librosa.display.waveshow(data,sr=sr,alpha=0.8) plt.subplot(1,2,2) librosa.display.waveshow(data_stretch,sr=sr,alpha=0.8) plt.show() plt.close()
소리 데이터에 librosa.effects.time_stretch함수를 사용하여 스트레칭을 적용한다. rate를 0.8으로 주면 재생시간을 0.8배로 줄인다.
원본 데이터와 비교해 확인하면 시간의 길이가 대략 40초에서 32초 정도로 줄어든 것을 확인할 수 있다.