-
python-07 pandas코딩/python 2023. 5. 4. 19:44
1. pandas
pandas 관계형 또는 레이블이 된 데이터를 분석하고 처리할 수 있는 라이브러리이다. 행과 열로 만들어진 데이터 객체를 3만들 수 있으며 대용량 데이터를 처리하기에 용이하다.
2. Series
import pandas as pd from pandas import Series, DataFramepandas 모듈을 불러와 pd로 사용한다. pandas 모듈에서 Series 함수와 DataFrame 함수를 불러온다.
fruit = Series([2500,3800,1200,6000], index=['apple','banana','peer','cherry']) fruit apple 2500 banana 3800 peer 1200 cherry 6000 dtype: int64print(fruit.values) print(fruit.index) [2500 3800 1200 6000] Index(['apple', 'banana', 'peer', 'cherry'], dtype='object')Series 객체는 index와 value로 이루어져있으며 1차원 배열의 값에 인덱스를 라벨링할 수 있다.
fruit.name = 'fruitPrice' fruit.index.name = 'fruitName' print(fruit)index의 이름과 Series 객체의 이름을 정할 수 있다.
fruit= Series([2500,3800,1200,6000], index = ['apple','banana','peer','cherry']) new_fruit = fruit.drop('banana') new_fruit apple 2500 peer 1200 cherry 6000 dtype: int64원하는 데이터를 삭제한 새로운 객체를 생성할 수 있다.
3. DataFrame
fruitData = {'fruitName':['apple','banana','cherry','peer'], 'fruitPrice':[2500,3800,6000,1200], 'num':[10,5,3,8] DataFrame(fruitData) fruitName fruitPrice num 0 apple 2500 10 1 banana 3800 5 2 cherry 6000 3 3 peer 1200 8DataFrame은 2차원 리스트를 값으로 가지며 2차원이므로 행과 열의 index를 가진다. 즉 columns, index, values로 구성된다.
fruitFrame = DataFrame(fruitData, columns=['fruitPrice','num','fruitName']) fruitFrame fruitPrice num fruitName 0 2500 10 apple 1 3800 5 banana 2 6000 3 cherry 3 1200 8 peer칼럼의 순서를 지정할 수 있다.
fruitFrame['fruitName'] 0 apple 1 banana 2 cherry 3 peer Name: fruitName, dtype: object원하는 열의 데이터만 볼 수 있다.
fruitFrame['year'] =2023 fruitFrame fruitPrice num fruitName year 0 2500 10 apple 2023 1 3800 5 banana 2023 2 6000 3 cherry 2023 3 1200 8 peer 2023새로운 행을 추가할 수 있다.
variable = Series([4,2,1],index=[0,2,3]) fruitFrame['stock'] = variable fruitFrame fruitPrice num fruitName year stock 0 2500 10 apple 2023 4.0 1 3800 5 banana 2023 NaN 2 6000 3 cherry 2023 2.0 3 1200 8 peer 2023 1.00,2,3의 인덱스에 4,2,1의 값을 가진 행을 추가한다. 지정되지 않은 값은 NaN으로 표시된다.
4. Data Frame 슬라이싱
fruitFrame = DataFrame(fruitData, index=fruitData['fruitName'], columns = ['fruitPrice', 'num']) fruitFrame fruitPrice num apple 2500 10 banana 3800 5 cherry 6000 3 peer 1200 8인덱스를 fruitName으로 지정하고 칼럼은 fruitPrice와 num으로 지정한다.
fruitFrame1 = fruitFrame.drop(['banana','peer']) fruitFrame1 fruitPrice num apple 2500 10 cherry 6000 3Seies 객체와 마찬가지로 drop을 사용하여 새로운 버전을 만든다.
fruitFrame.drop('apple',axis =0) num fruitPrice banana 5 3800 cherry 3 6000 peer 8 1200 fruitFrame.drop('num',axis =1) fruitPrice apple 2500 banana 3800 cherry 6000 peer 1200axis 속성을 사용하여 원하는 행과 열을 드랍할 수 있다.
print(fruitFrame[1:3]) fruitFrame['banana':'cherry'] fruitPrice num banana 3800 5 cherry 6000 3 fruitPrice num banana 3800 5 cherry 6000 30행과 4행의 index은 apple과 peer를 제외하고 1:3까지 슬라이싱 할 수 있다. 인덱스 이름으로도 슬라이싱할 수 있다.
5. DataFrame 정렬
fruitName = fruitData['fruitName'] fruitFrame = DataFrame(fruitData, index = fruitName, columns = ['num','fruitPrice']) fruitFrame num fruitPrice apple 10 2500 banana 5 3800 cherry 3 6000 peer 8 1200데이터 프레임 객체를 생성한다.
fruitFrame.sort_index(ascending = False) num fruitPrice peer 8 1200 cherry 3 6000 banana 5 3800 apple 10 2500반대 순서로 정렬한다.
fruitFrame.sort_values(by =['fruitPrice','num']) num fruitPrice peer 8 1200 apple 10 2500 banana 5 3800 cherry 3 60001순위 fruitPrice 2순위 num 값으로 정렬한다.
fruit.sort_values(ascending=True) peer 1200 apple 2500 banana 3800 cherry 6000 dtype: int64데이터를 정렬한다.
6. 기초분석(기술 통계량)
# count NA를 제외한 개수 # min, max 최소, 최대값 # sum 합 # comprod 누적합 # mean 평균 # median 중앙값 # quantile 분위수 # var 표본분산 # std 표본 정규분산 # describe 요약 통계량german_sample = pd.read_csv('http://freakonometrics.free.fr/german_credit.csv') type(german_sample) pandas.core.frame.DataFramegerman 데이터가 저장되어 있는 csv 파일을 pd.read를 사용해 불러와 데이터 프레임을 생성한다.
german_sample.columns.values array(['Creditability', 'Account Balance', 'Duration of Credit (month)', 'Payment Status of Previous Credit', 'Purpose', 'Credit Amount', 'Value Savings/Stocks', 'Length of current employment', 'Instalment per cent', 'Sex & Marital Status', 'Guarantors', 'Duration in Current address', 'Most valuable available asset', 'Age (years)', 'Concurrent Credits', 'Type of apartment', 'No of Credits at this Bank', 'Occupation', 'No of dependents', 'Telephone', 'Foreign Worker'], dtype=object)인덱스를 보여준다.
german = german_sample[['Creditability','Duration of Credit (month)', 'Purpose','Credit Amount']] german Creditability Duration of Credit (month) Purpose Credit Amount 0 1 18 2 1049 1 1 9 0 2799 2 1 12 9 841 3 1 12 0 2122 4 1 12 0 2171 ... ... ... ... ... 995 0 24 3 1987 996 0 24 0 2303 997 0 21 0 12680 998 0 12 3 6468 999 0 30 2 6350 1000 rows × 4 columns데이터를 출력하면 'Creditability','Duration of Credit (month)', 'Purpose','Credit Amount' 의 처음과 끝을 보여준다.
german.min() Creditability 0 Duration of Credit (month) 4 Purpose 0 Credit Amount 250 dtype: int64 german.max() Creditability 1 Duration of Credit (month) 72 Purpose 10 Credit Amount 18424 dtype: int64 german.mean() Creditability 0.700 Duration of Credit (month) 20.903 Purpose 2.828 Credit Amount 3271.248 dtype: float64각 데이터들의 최소값, 최대값, 평균값을 볼 수 있다.
german.describe() Creditability Duration of Credit (month) Purpose Credit Amount count 1000.000000 1000.000000 1000.000000 1000.00000 mean 0.700000 20.903000 2.828000 3271.24800 std 0.458487 12.058814 2.744439 2822.75176 min 0.000000 4.000000 0.000000 250.00000 25% 0.000000 12.000000 1.000000 1365.50000 50% 1.000000 18.000000 2.000000 2319.50000 75% 1.000000 24.000000 3.000000 3972.25000 max 1.000000 72.000000 10.000000 18424.00000describesms 기술적 통계량의 조금을 보여준다.
german = german_sample[['Duration of Credit (month)', 'Credit Amount', 'Age (years)']] german.head() Duration of Credit (month) Credit Amount Age (years) 0 18 1049 21 1 9 2799 36 2 12 841 23 3 12 2122 39 4 12 2171 38head는 데이터의 처음 부분을 조금 보여주며 데이터를 확인할 때 주로 쓰인다.
german.corr() Duration of Credit (month) Credit Amount Age (years) Duration of Credit (month) 1.000000 0.624988 -0.037550 Credit Amount 0.624988 1.000000 0.032273 Age (years) -0.037550 0.032273 1.000000corr메소드를 사용하여 각 데이터들의 상관관계를 확인할 수 있다.
7. groupby
german = german_sample[['Credit Amount','Type of apartment']] german_grouped = german['Credit Amount'].groupby(german['Type of apartment']) german_grouped.mean() Type of apartment 1 3122.553073 2 3067.257703 3 4881.205607 Name: Credit Amount, dtype: float64german 데이터의 'Credit Amount','Type of apartment'를 가져오고 'Credit Amount'를 'Type of apartment' 의 값에 따라 groupby할 수 있다.
8. pivot table
births = pd.read_csv('https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv') births.head() year month day gender births 0 1969 1 1.0 F 4046 1 1969 1 1.0 M 4440 2 1969 1 2.0 F 4454 3 1969 1 2.0 M 4548 4 1969 1 3.0 F 4548생일 데이터를 깃허브에서 가져온다.
births['decade'] = births['year'] // 10 * 10 births.head() year month day gender births decade 0 1969 1 1.0 F 4046 1960 1 1969 1 1.0 M 4440 1960 2 1969 1 2.0 F 4454 1960 3 1969 1 2.0 M 4548 1960 4 1969 1 3.0 F 4548 196010으로 나머지를 하고 다시 10을 곱해 10년 단위를 가진 decade를 만든다.
births.pivot_table('births', index='decade', columns='gender', aggfunc='sum') gender F M decade 1960 1753634 1846572 1970 16263075 17121550 1980 18310351 19243452 1990 19479454 20420553 2000 18229309 19106428사용할 데이터는 births, index가 decade, columns가 gender이고 집계함수는 sum이다.
births.pivot_table('births', index='year', columns='gender', aggfunc='sum').plot()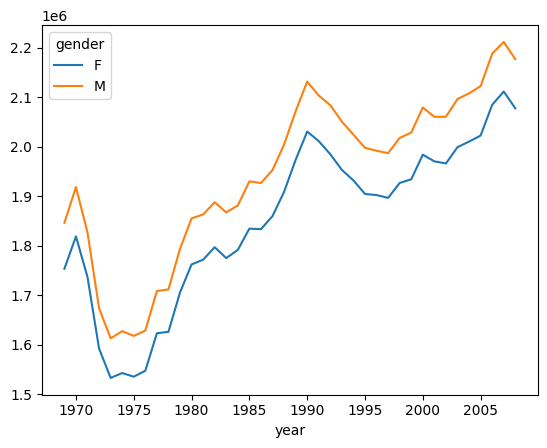
plot을 이용하여 간단한 그림으로 표현한다.
'코딩 > python' 카테고리의 다른 글
python-09 크롤링 (0) 2023.06.19 python-08 matplotlib (0) 2023.05.04 python-06 numpy (0) 2023.05.04 python-05 예외처리 (0) 2023.05.02