-
이미지 처리-7 객체 추적이미지 처리 2023. 6. 19. 18:50
1. 평균 이동 추적

평균 이동 추적은 객체의 픽셀 분포를 기반으로 객체를 추적하는 방법이다. 가장 먼저 추적할 창인 빨간색 창을 선택하고 추적 창 내부에서 히스토그램 역투영을 계산한다. 역투영은 노란 창의 분포를 나타내는 히스토그램과 현재 창의 히스토그램을 비교하여 추적 대상에 속할 확률을 계산한다. 역투영 이미지에서 최댓값을 찾아서 추적 창의 위치를 업데이트하는 것을 일정 조건이 충족할 때까지 계속 반복하는 방법이다.
import cv2 import os import numpy as np os.chdir('C:/Users/dotor/OneDrive/바탕 화면//jupyter/2. image') track_window = None roi_hist = None trem_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT,10,1) cap =cv2.VideoCapture('./picture/slow_traffic_small.mp4') ret, frame = cap.read() x, y,w,h =cv2.selectROI('roi',frame,False,False) print(x,y,w,h) roi = frame[y: y+h, x: x+w] hsv_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV) roi_hist = cv2.calcHist([hsv_roi], [0],None, [180],[0,180]) cv2.normalize(roi_hist,roi_hist, 0,255,cv2.NORM_MINMAX) track_window = (x,y,w,h) while True: ret, frame = cap.read() if not ret: break hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) dst = cv2.calcBackProject([hsv],[0],roi_hist, [0,180],1) _, track_window = cv2.meanShift(dst, track_window, trem_crit) x,y,w,h = track_window print(x,y,w,h) cv2.rectangle(frame, (x,y), (x+w, y+h),(0,255,0),2) cv2.imshow('frame',frame) if cv2.waitKey(30) & 0xFF == ord('q'): exit() cap.release() cv2.destroyAllWindows()
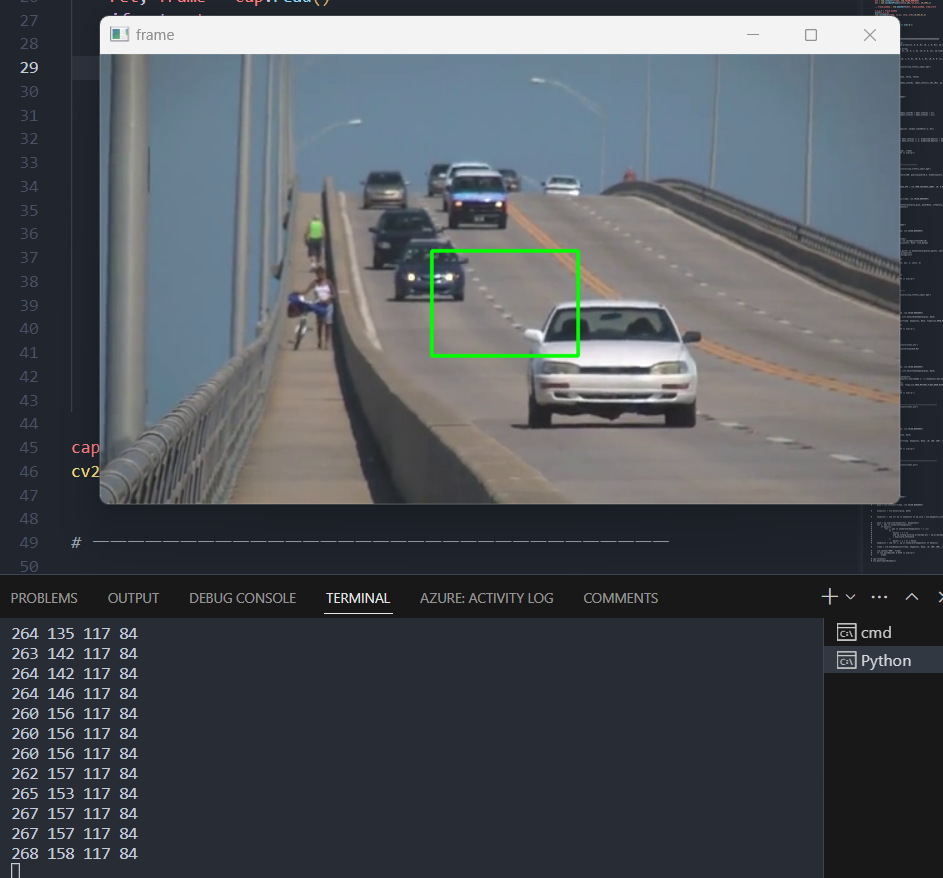
track_window에 추적창의 좌표와 크기를 저장하고, roi_hist에 객체의 히스토그램, term_crit에 알고리즘을 종료하는 조건을 정의한다. cv2.TERM_CRITERIA_EPS와 cv2.TERM_CRITERIA_COUNT를 or 연산으로 결합하여 사용하며 특정 정확도와 최대 반복 횟수를 지정한다.
videocapture으로 파일을 열어주고 cap.read로 파일 정보를 저장한다. selectROI 함수는 구역을 지정할 수 있는 함수이고 이름은 roi, 프레임에는 해당 프레임, 십자선 여부와 왼쪽 상단 좌표 기준으로 설정한다. 여기서 사용자가 선택한 영역을 x, y, w, h에 돌려받는다.
x, y, w, h 좌표들로 roi 영역을 계산하고 이미지를 hsv로 변환하면 calcHist에서 이미지의 색상의 분포를 히스토그램으로 계산할 수 있다. cv2.normalize를 이용하여 해당 히스토그램을 정규화한다.
영상이 실행 중일 때 calcBackProject는 hsv이미지를 사용하여 역투영 이미지를 계산한다. 해당 추적창과 hsv이미지의 0번 채널에 대해 역투영을 계산한다.
cv2.meanShift 함수를 사용하여 객체의 위치를 업데이트한다. 역투영 이미지와 추적 창의 좌표, 알고리즘 종료 조건을 넣어서 실행한다. meanshift 알고리즘은 조건이 충족할 때까지 해당 track_window를 역투영 계산하여 track_window에 업데이트한다.
코드를 실행해 보면 추적 개체로 지정한 창이 최대한 픽셀을 지속적으로 비교해 가면서 이동하는 것을 볼 수 있다.
2. 칼만 필터

칼만 필터는 상태 추정에 사용되는 필터로 객체추적에도 사용된다. 칼만 필터의 원리는 다음의 값을 확률적으로 예측하고 예측값과 관측값을 비교하여 보정과 추정을 실행한다. 이 과정을 반복하는 것이며 직전 값을 활용하는 특성을 가진 재귀필터이다.
재귀필터의 특성으로 직전 추정값과 예측값만 기억하면 되기 때문에 기존의 데이터의 필요성이 없어져 메모리의 부담을 줄일 수 있지만 어느 정도의 보정이 이루어져야 추정값에 대한 신뢰가 쌓인다.
또한 칼만필터는 이러한 선형적인 특성 때문에 시간에 따라 선형적이고 정규분포인 데이터에만 정확하게 동작한다.
kalman = cv2.KalmanFilter(4,2) kalman.measurementMatrix = np.array([[1, 0, 0, 0], [0, 1, 0, 0]], np.float32) kalman.transitionMatrix = np.array( [[1, 0, 1, 0], [0, 1, 0, 1], [0, 0, 1, 0], [0, 0, 0, 1]], np.float32 ) kalman.processNoiseCov = ( np.array([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]], np.float32) * 0.05 ) cap = cv2.VideoCapture('./picture/slow_traffic_small.mp4') ret, frame =cap.read() print(ret, frame) bbox_info = cv2.selectROI(frame, False, False) print(bbox_info) kalman.statePre = np.array([bbox_info[0], [bbox_info[1]],[0],[0]], np.float32) while True: ret, frame = cap.read() if not ret: print("프레임 읽기 실패") break kalman.correct( np.array( [ [np.float32(bbox_info[0] + bbox_info[2] / 2)], [np.float32(bbox_info[1] + bbox_info[3] / 2)], ] ) ) kalman.predict() predicted_bbox = tuple(map(int, kalman.statePost[:2, 0])) cv2.rectangle( frame, (predicted_bbox[0] - bbox_info[2] // 2, predicted_bbox[1] - bbox_info[3] // 2), (predicted_bbox[0] + bbox_info[2] // 2, predicted_bbox[1] + bbox_info[3] // 2), (0, 255, 0), 2, ) cv2.imshow("Kalman Traking", frame) if cv2.waitKey(30) & 0xFF == ord("q"): exit() cap.release() cv2.destroyWindow()

4개의 상태변수와 2개의 관측변수를 가지는 칼만행렬을 생성한다. 예측하고 싶은 것은 영상의 박스객체이고 이 박스객체는 x축, y축의 평면으로 이루어져 있기 때문에 x, y 두 가지의 관측변수를 가지면서 각 축이 변화할 수 있는 방향은 +,- 두 가지이므로 4개의 상태변수를 가진다.
관측변수와 상태 변수 간의 관계를 나타내는 2*4 행렬, 현재 상태 변수와 다음 상태 변수와의 관계를 나타내는 4*4 행렬, 변수의 변화에 대한 각 변수가 서로 독립적이며 분산이 1인 정규 분포를 따르는 노이즈 공분산 행렬을 생성한다.
이후에 동영상을 불러오고 관심영역을 지정하는 부분을 저장하는 코드를 작성한다. 관심 영역의 x, y 좌표의 초기값을 모르기 때문에 0으로 설정해서 kalman.statePre 변수에 저장한다.
kalman.correct 함수는 예측에 대한 보정을 진행한다. 영상의 가로, 세로 중심 값을 넣어주고 predict 함수로 보정값을 바탕으로 예측한다. statePost 함수로 예측된 상자 좌표를 구한다. 예측된 벡터에서 [:2, 0]으로 x, y좌표만 가지고 와서 정수로 변환하고 튜플 형태로 저장한다. 이제 예측된 좌표를 사각형으로 그리며 확인한다.
3. 특징점 기반 추적
특징점 기반 추적은 이미지에서 주요한 특징점을 찾아서 객체를 추적하는 방법이다. 특징점 검출 알고리즘에는 sifr, surf, orb 등이 있으며 이를 이용하여 특징점을 계산하고 이전 프레임과 다음 프레임의 특징점을 매칭하여 이동 벡터를 계산하고 객체의 위치를 업데이트하는 과정을 반복한다.
cap = cv2.VideoCapture('./picture/slow_traffic_small.mp4') feature_params = dict(maxCorners=100, qualityLevel=0.3, minDistance=7, blockSize=7) lk_params = dict( winSize=(30, 30), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03), ) ret, prve_frame = cap.read() prev_gray = cv2.cvtColor(prve_frame, cv2.COLOR_BGR2GRAY) print(prev_gray.shape) prev_corner = cv2.goodFeaturesToTrack(prev_gray, mask=None, **feature_params) prev_points = prev_corner.squeeze() color = (0, 255, 0) while True: ret, frame = cap.read() if not ret: print("프레임 읽기 실패") break gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) print(gray.shape) print("lk_params", lk_params) next_points, status, _ = cv2.calcOpticalFlowPyrLK( prev_gray, gray, prev_points, None, **lk_params ) for i, (prev_point, next_point) in enumerate(zip(prev_points, next_points)): x1, y1 = prev_point.astype(int) x2, y2 = next_point.astype(int) print(x1, y1, x2, y2) cv2.circle(frame, (x2, y2), 3, color, 3) cv2.imshow("...", frame) prev_gray = gray.copy() prev_points = next_points if cv2.waitKey(30) & 0xFF == ord("q"): break cap.release() cv2.destroyAllWindows()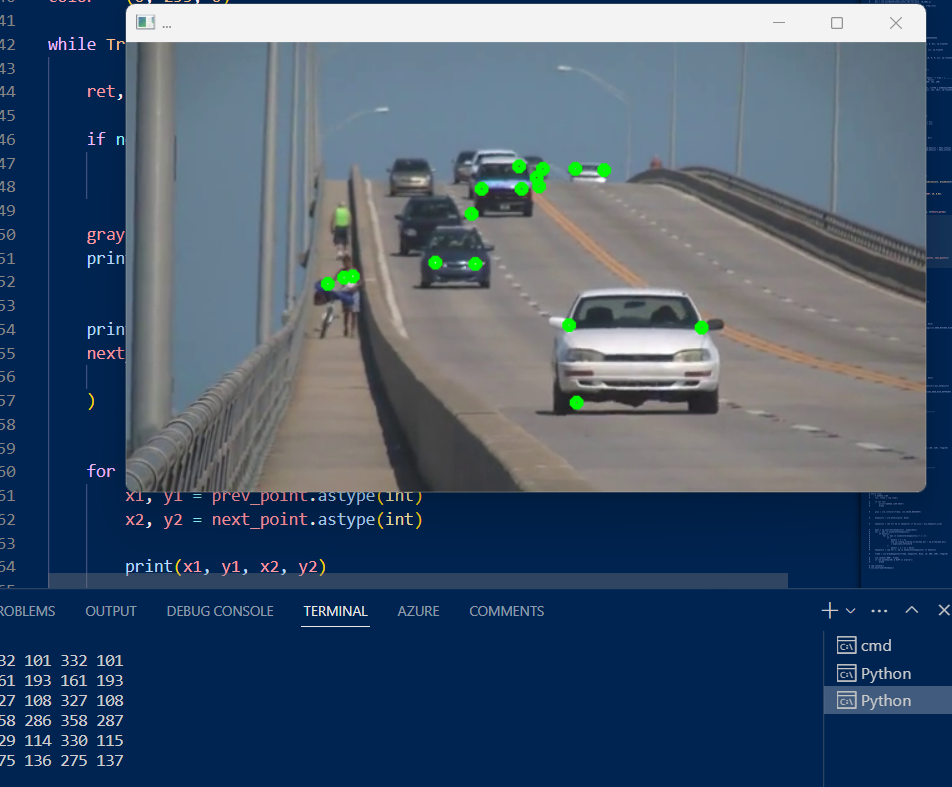
파일을 열고 특징점 검출에 사용되는 파라미터들을 정의한다. maxCorners는 검출할 특징점의 최대 개수, qualityLevel은 특징점으로 인정되기 위한 최소품질, minDistance는 특징점들 간의 최소거리, blockSize는 특징점 검출을 위한 픽셀의 범위를 나타내며 홀수로 지정한다.
알고리즘에 사용되는 파라미터 또한 정의한다. winSize는 특징점 계산을 위한 윈도우 크기이며 작을수록 작은 이동에, 클수록 큰 이동에 민감하게 반응한다. maxLevel은 피라미드 레벨 수로 이미지 피라미드로 광학 계산을 실시하는데 이 피라미드의 레벨이 높을수록 계산이 오래 걸리지만 정확한 결과를 얻을 수 있다. criteria는 알고리즘의 종료 기준으로 기준과 반복 횟수를 각각 설정한다.
이미지를 프레임을 읽어오고 cv2.goodFeaturesToTrack 함수로 특징점을 검출한다. 그레이 이미지를 넣어주고 mask를 none으로 설정해 전체영역을 지정하며 특징점 검출에 필요한 파라미터들을 전달한다. **은 딕셔너리 형태의 변수만 받겠다는 의미이다. 2차원 배열을 반환하기 때문에 검출된 값을 squeeze 함수로 2차원 배열을 1차원 배열로 차원을 축소하여 좌표로 저장한다.
calcOpticalFlowPyrLK 함수로 현재 프레임과 이전 프레임의 차이를 계산한다. 이전 프레임과 현재 프레임의 그레이스케일 이미지, 특징점 좌표를 넣고 마스크를 전체로 설정하여 광학 계산에 필요한 알고리즘을 전달한다. 이 함수는 이전 프레임으로 추정한 현재 프레임의 특징점 좌표, 특징점 추적의 성공여부, 에러 3가지를 반환한다.
이전 특징점 좌표와 현재 특징점 좌표를 zip 함수를 사용하여 엮을 수 있다. 개수가 같은 딕셔너리이기 때문에 하나씩 꺼내서 묶어버릴 수 있다. 이것을 enumrate로 순서를 매겨주면 해당 프레임의 인덱스, 현재 좌표, 이전 좌표를 가지게 된다. 과거 좌표와 현재 좌표를 각각 x1, y1, x2, y2에 저장한다.
현재 좌표를 기준으로 원을 그려서 특징점을 그릴 수 있으며 이전 그레이 스케일을 복사하여 업데이트하고 prev_points = next_points 코드를 작성하여 계속해서 현재의 특징점좌표를 갱신한다.
4. sift(Scale-Invariant Feature Transform)
sift 알고리즘은 이미지의 크기와 회전이 불변하는 특징점을 추출하는 방법이다. sift는 다양한 환경에서 강력한 특징점 추출이 가능하나 계산비용이 상대적으로 높기 때문에 대규모 이미지나 실시간 처리에는 부적합하다.
cap = cv2.VideoCapture('./picture/slow_traffic_small.mp4') sift = cv2.SIFT_create() while True: ret, frame = cap.read() if not ret: break gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) keypoints, descriptors = sift.detectAndCompute(gray, None) frame = cv2.drawKeypoints(frame, keypoints, None, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) cv2.imshow('shift',frame) if cv2.waitKey(30) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()
while문으로 동영상 프레임을 읽어오고 sift.detectAndCompute에 그레이 스케일 이미지를 넣어서 전체영역에서 특징점을 검출한다. 특징점의 리스트와 특징점의 배열을 출력한다.
이 키포인트를 가지고 drawKeypoints 함수를 사용하여 이미지 위에 특징점을 그린다. 입력 이미지와, 키 포인트 리스트를 전달하고 none으로 설정하면 새로운 이미지를 생성하여 그린다.
cap = cv2.VideoCapture('./picture/vtest.avi') sift = cv2.SIFT_create(contrastThreshold=0.02) max_ketpoints =30 while True: ret, frame = cap.read() if not ret: break gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) keypoints, descriptors = sift.detectAndCompute(gray, None) if len(keypoints) > max_ketpoints: keypoints =sorted(keypoints,key=lambda x: -x.response)[:max_ketpoints] frame = cv2.drawKeypoints( frame, keypoints, None, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS ) cv2.imshow('shift',frame) if cv2.waitKey(30) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()
SIFT_create 함수에서 contrastThreshold를 0.02로 설정하면 주변 픽셀과의 대비가 0.02 이상인 영역만을 키포인트를 추출하는 데 사용한다. 임계값이 낮을수록 더 많은 특징점들이 검출되며 노이즈가 포함된다.
만약 검출된 키포인트가 max_keypoints보다 많다면 키포인트를 -x.response로 내림차순 정렬하여 max_keypoints의 개수만큼만 슬라이싱하여 선택한다.
이제 키포인트를 그려서 확인하면 이전보다 특징점의 개수가 설정한 30개로 제한되어 출력되는 것을 확인할 수 있다.
5. orb (Oriented FAST and Rotated BRIEF)
orb 알고리즘은 FAST (Features from Accelerated Segment Test) 특징점 검출기와 BRIEF (Binary Robust Independent Elementary Features) 디스크립터의 결합이며 sift 알고리즘과 달리 회전된 이미지에서도 일관된 특징점을 검출할 수 있으며 brief 디스크립터가 이진 형태로 구성되어 계산속도가 빠르지만 비교적 덜 정확하다.
cap = cv2.VideoCapture("./picture/vtest.avi") orb = cv2.ORB_create() while True: ret, frame = cap.read() if not ret: break gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) keypoints = orb.detect(gray, None) frame = cv2.drawKeypoints(frame, keypoints, None, (0, 150, 220), flags=0) cv2.imshow("ORB", frame) if cv2.waitKey(30) & 0xFF == ord("q"): break cap.release() cv2.destroyAllWindows()
sift와 동일한 방식으로 특징점을 추출하고 확인할 수 있다.
cap = cv2.VideoCapture("./picture/slow_traffic_small.mp4") orb = cv2.ORB_create() min_keypoint_size = 10 duplicate_threshold = 10 while True: ret, frame = cap.read() if not ret: print("프레임 읽기 실패") break gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) keypoints = orb.detect(gray, None) keypoints = [kp for kp in keypoints if kp.size > min_keypoint_size] mask = np.ones(len(keypoints), dtype=bool) for i, kp1 in enumerate(keypoints): if mask[i]: for j, kp2 in enumerate(keypoints[i + 1 :]): if ( mask[i + j + 1] and np.linalg.norm(np.array(kp1.pt) - np.array(kp2.pt)) < duplicate_threshold ): mask[i + j + 1] = False keypoints = [kp for i, kp in enumerate(keypoints) if mask[i]] frame = cv2.drawKeypoints(frame, keypoints, None, (0, 200, 150), flags=0) cv2.imshow("ORB", frame) if cv2.waitKey(30) & 0xFF == ord("q"): break cap.release() cv2.destroyAllWindows()
orb에서 중복된 특징점을 제거하고 일정 수준 이하의 키포인트를 제거한다. kp for kp in keypoints if kp.size > min_keypoint_size를 사용하여 10보다 작은 수준의 키포인트를 제거하면서 노이즈라고 생각되는 값들을 지울 수 있다.
np.ones에 키포인트의 개수만큼 1로 채워서 불리안타입으로 변환하여 마스크를 생성한다. 리스트 내의 모든 요소가 true로 초기화된 배열이 생성된다.
enumrate로 키포인트에서 순서와 kp1을 뽑아낸다. 만약 mask가 true인 경우 초기 값은 모두 true이므로 모든 값에 대하여 반복문을 실행할 것이다. 현재 키포인트 값 kp1에서 1을 더하고 나머지를 슬라이싱 해서 kp2에 저장한다.
kp1에는 현재 키포인트 kp2에는 다음 키포인트부터 끝까지의 키포인트가 저장될 것이고 이것을 처음부터 끝까지 순회하면서 조건문을 실행한다. mask가 true일 때 kp1과 나머지 모든 값들(kp2)과의 유클라디안 거리계산을 통해서 위에서 설정한 duplicate_threshold 10보다 작다면 mask를 false로 업데이트한다.
mask 업데이트를 완료하면 다시 한번 true인 값만 키포인트에서 뽑아내어 출력하면 유클라디안 거리계산 10 미만이 제거된 키포인트만을 얻을 수 있다.
6. 특징점 매칭
import cv2 img1 = cv2.imread("./picture/car.jpg", cv2.IMREAD_GRAYSCALE) img2 = cv2.imread("./picture/car.jpg", cv2.IMREAD_GRAYSCALE) orb = cv2.ORB_create() keypoint01, descriptor01 = orb.detectAndCompute(img1, None) keypoint02, descriptor02 = orb.detectAndCompute(img2, None) bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True) matches = bf.match(descriptor01, descriptor02) matches = sorted(matches, key=lambda x:x.distance) result = cv2.drawMatches(img1, keypoint01, img2, keypoint02, matches[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS) cv2.imshow("Matches", result) cv2.waitKey(0) num_matches = len(matches) print(num_matches) num_good_matches = sum(1 for m in matches if m.distance < 50) matching_percent = (num_good_matches / num_matches) * 100 print("매칭 퍼센트 : %.2f%%" % matching_percent)
orb를 사용해 각각의 이미지의 특징점을 검출한다. cv2.BFMatcher를 사용하여 bf 객체를 생성한다. 거리측정 방식과 crosscheck=Tre으로 양방향 매칭을 수행할 수 있도록 한다.
bf.match 함수에 디스크립터 인자를 전달하여 매칭을 실시하고 거리에 따라 정렬한다. 이후에 두 이미지를 전달하고 상위 20개 매칭을 이미지로 그린다.
매칭의 퍼센트를 계산하기 위해 50보다 작은 거리에 있는 매칭 결과들을 전체 매칭 결과로 나눠서 출력한다. 이미지를 확인해 보면 특징점들이 매칭된 것을 볼 수 있다.
'이미지 처리' 카테고리의 다른 글
이미지 처리-9 이미지 증강 (0) 2023.06.26 이미지 처리-8 이미지 라벨링 (0) 2023.06.19 이미지 처리-6 기본 동영상 처리 (0) 2023.06.19 이미지 처리-5 이미지 혼합 (0) 2023.06.19