-
sklearn-06 classification 1 logistic regression머신러닝/sklearn 2023. 5. 10. 18:03
1. logistic regression
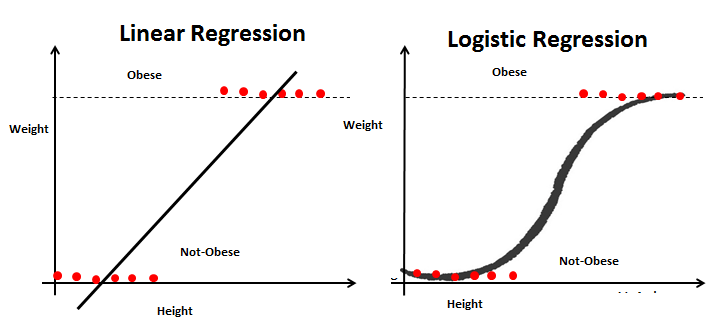
로지스틱 회귀는 이름은 회귀이지만 분류방식으로 작동한다. 데이터를 기준보다 작으면 0으로 분류하고 크면 1으로 분류한다.
로지스틱 회귀는 매우 효율적이고 엄청난 양의 계산 리소스를 필요로 하지 않기 때문에 널리 사용된다. 하지만 로지스틱 회귀는 비선형문제를 해결하는 데 사용할 수 없는 단점이 있다.
로지스틱 회귀와 선형회귀의 차이점은 로지스틱 회귀는 선형회귀에서 구하는 직선 대신 시그모이드 함수를 이용하여 s곡선을 통해 0또는 1로 분류하는 분류 기법이다. 모든 데이터가 직선 형태로 나오지 않기 때문에 다양한 데이터를 표현할 수 있다.
시그모이드함수는 결과 값을 0 또는 1로 반환하기 때문에 분류 문제에 유용하다.
2. 데이터 불러오기
import numpy as np import pandas as pd import sklearn import matplotlib.pyplot as plt from sklearn.datasets import load_iris iris = load_iris()필요한 모듈들을 불러오고 iris 데이터를 불러온다.
data = iris.data label =iris.target columns = iris.feature_names데이터 값과 라벨값, 칼럼값을 지정한다.
data = pd.DataFrame(data, columns = columns) data.head() sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 data.shape (150, 4)데이터 프레임을 만들어 head와 shape으로 데이터를 확인한다.
3. 데이터 쪼개기
from sklearn.model_selection import train_test_split X_train,X_test, y_train, y_test =train_test_split(data, label,test_size=0.2,random_state=2023)x(데이터값)은 대문자로 y(라벨값)은 소문자로 사용하며 학습데이터와 시험데이터로 분류한다. 테스트 데이터의 사이즈는 20프로이며 랜덤 스테이트는 2023으로 설정하여 랜덤하게 잘라준다.
from sklearn.linear_model import LogisticRegression lr = LogisticRegression()로지스틱 회귀 패키지를 불러주고 변수를 만든다.
lr.fit(X_train, y_train) /usr/local/lib/python3.10/dist-packages/sklearn/linear_model/_logistic.py:458: ConvergenceWarning: lbfgs failed to converge (status=1): STOP: TOTAL NO. of ITERATIONS REACHED LIMIT. Increase the number of iterations (max_iter) or scale the data as shown in: https://scikit-learn.org/stable/modules/preprocessing.html Please also refer to the documentation for alternative solver options: https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression n_iter_i = _check_optimize_result( LogisticRegression LogisticRegression()fit을 사용하여 데이터를 학습시킨다.
y_pred = lr.predict(X_test) y_pred array([2, 1, 1, 2, 1, 2, 1, 1, 0, 1, 0, 1, 0, 2, 0, 2, 0, 1, 0, 0, 1, 0, 2, 1, 0, 0, 0, 2, 1, 0]) y_test array([2, 1, 1, 2, 1, 2, 1, 1, 0, 1, 0, 1, 0, 2, 0, 2, 0, 1, 0, 0, 1, 0, 2, 1, 0, 0, 0, 2, 1, 0])predict를 사용하여 테스트 데이터로 라벨값을 예측해본다. y_test의 값과 일치한다.
from sklearn.metrics import accuracy_score결과를 확인하기 위한 모듈을 불러온다.
print('로지스틱 회귀 정확도:{:}'.format(accuracy_score(y_test, y_pred) * 100)) print('로지스틱 회귀 \n계수(w): {0}\n절편(b): {1}'.format( lr.coef_, lr. intercept_)) 로지스틱 회귀 정확도:100.0 로지스틱 회귀 계수(w): [[-0.44734561 0.8926404 -2.33623964 -1.03295779] [ 0.49390809 -0.33483512 -0.19125056 -0.85050783] [-0.04656248 -0.55780528 2.5274902 1.88346562]] 절편(b): [ 9.47258972 2.14495508 -11.6175448 ]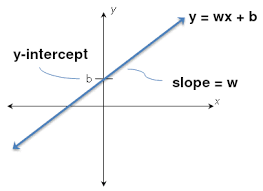
accuracy_score로 라벨의 예측값과 테스트값이 일치하는것을 알 수 있고 coef와 intercept를 통해 기울기와 절편 값을 확인할 수 있다.
현재 데이터에서 iris-setosa, iris-versicolour, iris-virginica 3개의 클래스와 sepal length, sepal width, petal length, sepal width 4개의 특성을 가지고 있다.
4개의 특성에 대한 각각의 기울기 4개를 가지며 절편은 클래스의 수만큼 값을 가진다.
'머신러닝 > sklearn' 카테고리의 다른 글
sklearn-08 classification 3 decision tree (0) 2023.05.10 sklearn-07 classification 2 svm (0) 2023.05.10 sklearn-04 preprocessing 4 categorical variable to numeric variable (0) 2023.05.07 sklearn-03 preprocessing 3 dimensionality reduction (0) 2023.05.07