-
1. categorical variable to numeric variable
범주형 변수를 수치형 변수로 나타낸다. 방법에는 Label Encoding, One-hot Encoding 등이 있다.
2. label encoding
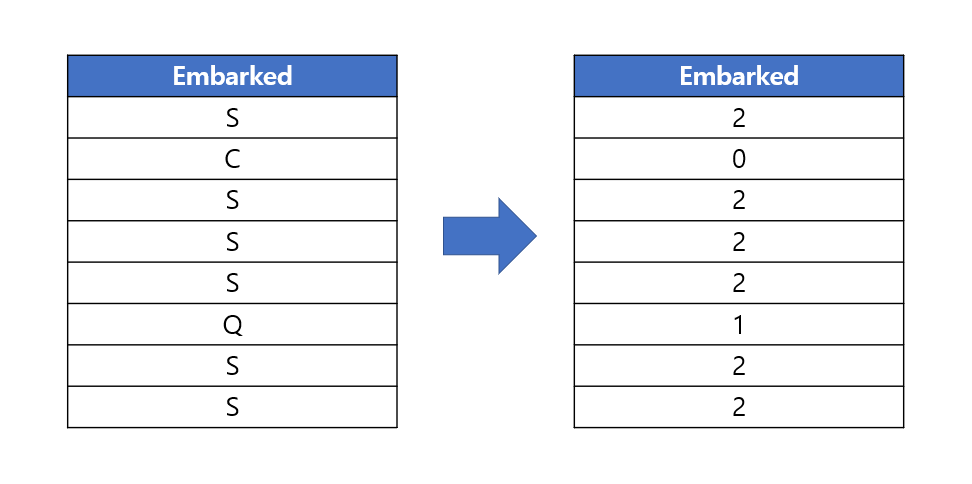
소형, 중형, 대형 같은 범주형 변수를 0, 1, 2의 수치형 변수로 바꿔주는 방법이다.
data = pd.read_csv(abalone_path,header=None,names=abalone_columns) label = data['Sex'] del data label 0 M 1 M 2 F 3 M 4 I .. 4172 F 4173 M 4174 M 4175 F 4176 M Name: Sex, Length: 4177, dtype: object전복 데이터를 불러와서 성별 데이터만 남긴다.
from sklearn.preprocessing import LabelEncoder labelEncode = LabelEncoder() encoded_label = labelEncode.fit_transform(label) encoded_label array([2, 2, 0, ..., 2, 0, 2])라벨 엔코딩 모듈을 불러오고 실행시킨다.
성별 데이터가 숫자로 바뀐것을 알 수 있다.
3. one-hot encoding
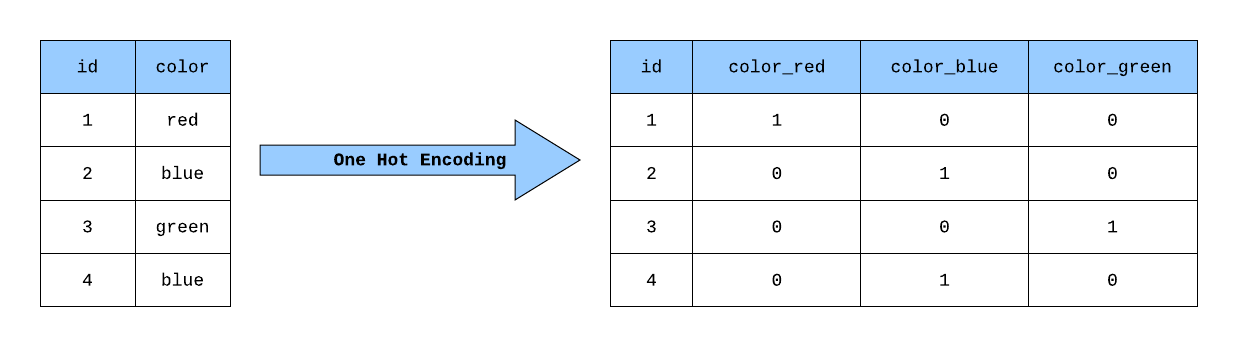
데이터의 차원을 종류만큼 변환하는 방법이며 독립적이며 연속적인 데이터를 얻을 수 있다.
from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(sparse=False)원핫엔코딩 모듈을 불러오고 실행한다. sparse 옵션은 true는 matrix 값을 반환하며 array 값을 얻기 위해 false를 준다.
one_hot_encoded = ohe.fit_transform(label.values.reshape((-1,1))) one_hot_encoded array([[0., 0., 1.], [0., 0., 1.], [1., 0., 0.], ..., [0., 0., 1.], [1., 0., 0.], [0., 0., 1.]])원핫앤코딩을 실행하여 원핫앤코딩 구조로 변환한다.
columns = np.concatenate([np.array(['label']),ohe.categories_[0]]) columns array(['label', 'F', 'I', 'M'], dtype=object)label+ F, I, M의 카테고리 정보를 concatenate를 사용하여 붙인다.
result = pd.DataFrame(data = np.concatenate([label.values.reshape((-1,1)), one_hot_encoded.reshape((-1,3))] ,axis=1),columns=columns) result.head(10) label F I M 0 M 0.0 0.0 1.0 1 M 0.0 0.0 1.0 2 F 1.0 0.0 0.0 3 M 0.0 0.0 1.0 4 I 0.0 1.0 0.0 5 I 0.0 1.0 0.0 6 F 1.0 0.0 0.0 7 F 1.0 0.0 0.0 8 M 0.0 0.0 1.0 9 F 1.0 0.0 0.0성별 데이터와, one_hot_encoded를 붙여서 데이터프레임을 만든다.
'머신러닝 > sklearn' 카테고리의 다른 글
sklearn-07 classification 2 svm (0) 2023.05.10 sklearn-06 classification 1 logistic regression (0) 2023.05.10 sklearn-03 preprocessing 3 dimensionality reduction (0) 2023.05.07 sklearn-02 preprocessing 2 sampling (0) 2023.05.07