-
sklearn-02 preprocessing 2 sampling머신러닝/sklearn 2023. 5. 7. 16:09
1. sampling
데이터의 불균형한 분포를 가지는 경우 오버 샘플링 또는 언더 샘플링을 실행한다.
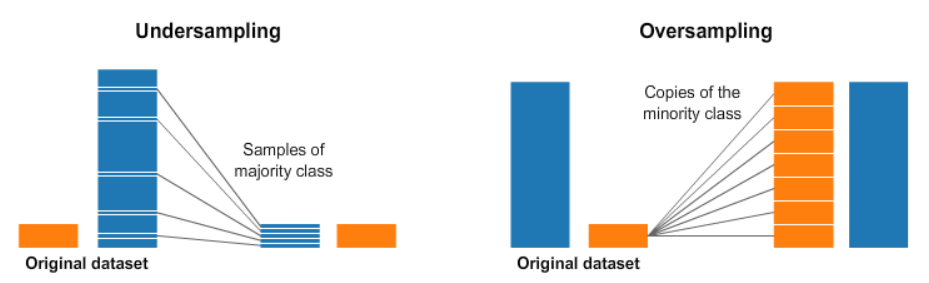
2. oversampling, undersampling
from imblearn.over_sampling import RandomOverSampler from imblearn.under_sampling import RandomUnderSampler ros = RandomOverSampler() rus = RandomUnderSampler()필요한 모듈을 불러오고 샘플링을 사용할 변수를 만든다.
oversampled_data, oversampled_label = ros.fit_resample(data, label) oversampled_data = pd.DataFrame(oversampled_data, columns=data.columns) #oversampling undersampled_data, undersampled_label = ros.fit_resample(data, label) undersampled_data = pd.DataFrame(undersampled_data, columns=data.columns) #undersamplingfit_resample으로 샘플링을 실행하고 데이터 프레임에 넣어준다.
print('원본데이터의 클래스 비율\n{0}'.format(pd.get_dummies(label).sum())) # dummies는 라벨의 데이터를 가져온다 print('\nRandom Over 샘플링 결과\n{0}'.format(pd.get_dummies(oversampled_label).sum())) print('\nRandom under 샘플링 결과\n{0}'.format(pd.get_dummies(undersampled_label).sum())) 원본데이터의 클래스 비율 F 1307 I 1342 M 1528 dtype: int64 Random Over 샘플링 결과 F 1528 I 1528 M 1528 dtype: int64 Random under 샘플링 결과 F 1307 I 1307 M 1307 dtype: int64샘플링한 결과를 확인한다. 오버샘플링은 최댓값에 맞추고 언더샘플링은 최솟값에 맞춘다.
오버, 언더 샘플링은 데이터를 증가, 감소시켰을 때 오히려 데이터가 과적합되거나 데이터 손실이 발생할 수 있기 때문에 smote를 사용한다.
3. smote
smote(Synthetic Minority Over-sampling Technique) 오버 샘플링 기법 중 하나이며 낮은 비율로 존재하는 데이터를 k-NN알고리즘을 이용하여 새롭게 생성하는 방법이다.
1. 소수 데이터의 특정 데이터와 가장 가까운 k개의 이웃을 선정한다.
2. 기준 데이터와 이웃 데이터를 선분으로 잇는다.
3. 선분 위에 새로운 데이터를 생성한다.
from imblearn.over_sampling import SMOTE smote = SMOTE(k_neighbors=5) # 점의 이웃의 개수를 기준으로 위치를 조정 from sklearn.datasets import make_classification data, label = make_classification(n_samples=1000, #표본 데이터의 수, 디폴트 100 n_features=2, #특성의 수, 디폴트 20 n_informative=2, #특성 중 종속 변수와 상관 관계가 있는 성분의 수, 디폴트 2 n_redundant=0, #특성 중 다른 특성의 선형 조합으로 나타나는 성분의 수, 디폴트 2 n_repeated=0,#특성의 중복 수 n_classes=3,#클래스의 개수 n_clusters_per_class=1,#클래스 당 클러스터의 수, 디폴트 2 weights=[0.05,0.15,0.8],#각 클래스에 할당된 표본 수 class_sep=0.8,#하이퍼큐브의 크기를 곱하는 계수, 디폴트 1 random_state=2019) #난수 발생 시드 label array([1, 1, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 0, 1, 2, 2, 2, 2, 2, 2, 0, 1, 2, 2, 1, 1, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 1, 2, 0, 0, 2, 1, 2, 1, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2, 1, 2, 2, 0, 2, 1, 1, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 0, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 0, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 1, 2, 2, 2, 0, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 0, 0, 0, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 1, 2, 2, 0, 2, 2, 2, 2, 2, 0, 2, 2, 0, 2, 1, 2, 2, 2, 1, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 1, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 1, 0, 2, 1, 2, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2, 0, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 0, 2, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 1, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 1, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 0, 2, 1, 2, 2, 2, 1, 2, 1, 0, 2, 2, 1, 1, 1, 2, 2, 0, 2, 1, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 2, 2, 2, 2, 1, 2, 2, 2, 2, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 0, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 1, 1, 2, 2, 2, 2, 1, 1, 2, 0, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 0, 2, 2, 2, 0, 1, 2, 1, 2, 2, 2, 2, 1, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 0, 1, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 1, 2, 1, 1, 2, 2, 2, 2, 2, 0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 2, 2, 1, 1, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 0, 2, 2, 2, 0, 1, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 0, 1, 2, 2, 1, 2, 2, 0, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 1, 1, 2, 2, 2, 2, 2, 1, 0, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 1, 2])make classfication으로 1~3 사이의 값을 무작위로 1000개 생성한다.
fig = plt.Figure(figsize=(12,6)) plt.scatter(data[:,0],data[:,1],c=label,linewidth=1,edgecolor='black')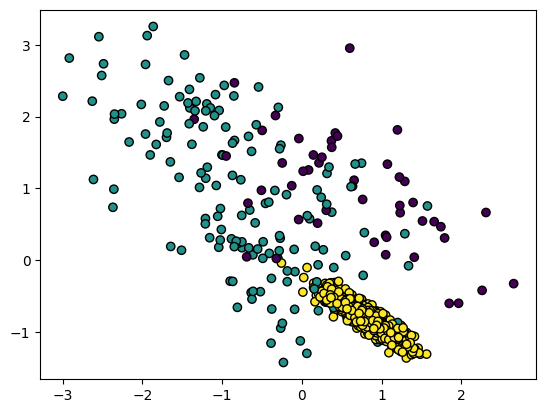
그림을 그리고 scatter로 표현한다.
smoted_data, smoted_label = smote.fit_resample(data,label) print('원본데이터 클래스 비율\n{0}'.format(pd.get_dummies(label).sum())) print('smoted데이터 클래스 비율\n{0}'.format(pd.get_dummies(smoted_label).sum())) 원본데이터 클래스 비율 0 53 1 154 2 793 dtype: int64 smoted데이터 클래스 비율 0 793 1 793 2 793 dtype: int64smote 기법으로 증식된 결과를 확인할 수 있다.
fig = plt.Figure(figsize=(12,6)) plt.scatter(smoted_data[:,0],smoted_data[:,1],c=smoted_label, linewidth=1,edgecolor='k')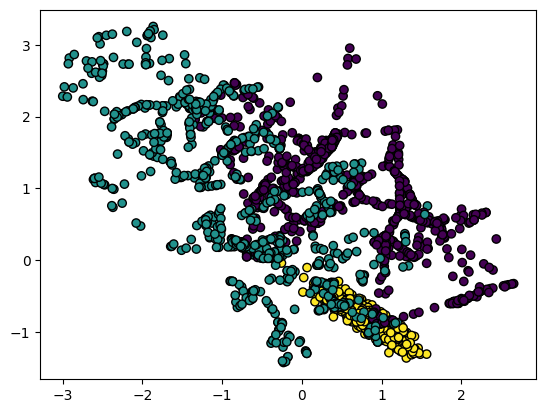
scatter를 하고 위의 그림과 비교해본다.
'머신러닝 > sklearn' 카테고리의 다른 글
sklearn-04 preprocessing 4 categorical variable to numeric variable (0) 2023.05.07 sklearn-03 preprocessing 3 dimensionality reduction (0) 2023.05.07 sklearn-05 모델 평가 지표 (0) 2023.05.04 sklearn-01 preprocessing 1 scaling (0) 2023.05.04